

Arbete pågår!
Denna sida är under uppbyggnad och innehåller både ofärdigt och ogranskat material. Läs med största försiktighet!
Vill du vara med och utveckla denna sida?
Innehåll att utforska


- Vi vet att artificiell intelligens (AI) kan hjälpa oss att hitta nya lösningar, diagnostisera sjukdomar, effektivisera energiförbrukning och mycket mer
- Vi vet att AI potentiellt utgör ett existentiellt hot mot mänskligheten
- Vi vet att AI kan hjälpa människor att lära
Vad är artificiell intelligens?
Artificiell intelligens
Inom artificiell intelligens (AI) försöker forskare bygga smarta maskiner eller datorprogram som klarar av att lösa svåra problem, som vanligtvis kräver mänsklig intelligens.

Expertsystem
Ett försök att nå intelligenta svar är att skapa så kallade expertsystem. Idén bygger på att försöka överföra mänskliga experters kunskaper in i datorprogram.
AI – en annorlunda revolution
Mänskligheten har stått inför flera tekniska revolutioner tidigare. Vad är annorlunda nu?
1 000 000 år sedan,
under stenåldern, började vi skapa och använda enkla verktyg.
10 000 år sedan,
under jordbruksrevolutionen, började vi odla vår mat och bygga fasta bosättningar.
5 000 år sedan
började vi använda skrivtekniker. Vi kunde nu kommunicera över generationer utan att vara begränsade till hörsägen.
500 år sedan
började vi använda tryckteknik för att massproducera texter och därmed sprida idéer på stor skala.
200 år sedan,
under industriella revolutionen, uppfanns telegrafen. Vi kunde nu kommunicera och sprida idéer i realtid mellan kontinenter.
30 år sedan,
under informationstekniska IT-evolutionen, uppfanns Internet och World Wide Web. Vi kunde nu sprida och konsumera idéer mellan “alla” människor.
Några viktiga iakttagelser:
- Tekniska utvecklingen går snabbare och snabbare – exponentiellt snabbt. 30 års utveckling gjorde inga större framsteg mellan 1000 till 970 år sedan. 30 års utveckling gjorde desto större skillnad i början på 1800-talet, men bleknar fortfarande i jämförelse med den samhällsförändring som skett de senaste 30 åren. I framtiden kommer steg om 30 år fortsätta medföra allt större utveckling.
- Hastigheten av utvecklingen är nu så snabb att världen är avsevärt annorlunda från en generation till nästa. Under en livstid har vi gått från att betala med kontanter, till betalkort, till internetbank, till Swish. I delar av världen kan man till och med betala genom ansiktsigenkänning.
- Det har varit människor som har drivit utvecklingen. Varje revolution har därför ständigt haft en stark drivkraft för människor att introducera nya verktyg som hjälper andra människor att snabbare och enklare ta nästa steg i utvecklingen.
- Människor har börjat producera stora mängder elektronisk data genom sitt användande av appar, sociala medier mm.
Så vad är det som gör att den tekniska utvecklingen är annorlunda idag?
- Till att börja med är hastigheten av utvecklingen nu så snabb att den utmanar en människas inlärningsförmåga.
- För det andra pågår det en artificiell revolution som utmanar människans roll i utveckling. Hur? Genom att AI lär sig själv med så kallad maskininlärning.
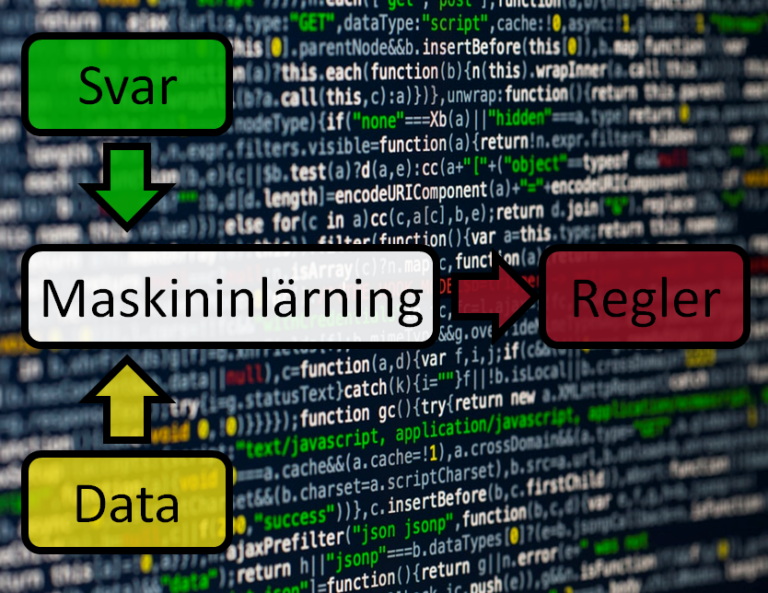
Maskininlärning
I maskininlärning byter vi angreppssätt för att nå AI, genom att introducera en helt ny idé. Istället för att programmera in de regler som vi känner till om hur världen fungerar så matar vi in exempel (data och svar) och tränar fram reglerna.

Vad har personerna på bilden gemensamt?
Svar:
Bilderna har genererats av ett artificiellt neuralt nätverk. Generera fler bilder.
AI-tillämpningar bortom tekniken
AI agenter används inte bara för att lösa tekniska problem, de kan även generera bilder och musik, till och med dikta ihop texter som aldrig tidigare skrivits.
Kreativ AI?
Är generativa nätverk (generative adversarial networks – GAN) ett första steg mot kreativ AI? Denna nätverkstyp introducerades första gången 2014. Kommer vi se en explosion av AI-assisterad kreativitet och nya användbara idéer de kommande 30 åren? Ändrar detta vad det innebär att vara kreativ, eller människa?

Kan väldigt mycket om väldigt lite
AI kommer sannolikt förändra våra liv minst lika mycket som internet gjorde, men än så länge är AI-agenter oftast bara extremt duktiga på att besvara extremt specifika frågor.

Varför behövs intelligens?
En bild från en vanlig mobilkamera innehåller cirka 5 miljoner pixlar. Även om bilden skulle vara svartvit så kan pixlarna kombineras i fler kombinationer än vad det finns atomer i hela universum.

Intelligens – att begränsa sin vy?
När forskare tog fram schackspelande spelmotorer blev de snabbt överlägsna människor trots att spelmotorerna egentligen inte var speciellt intelligenta.

Bortom mänsklig intelligens
En vanlig strategi för att skapa AI-agenter är att låta dem träna på data som bygger på hur människor gjort i liknande situationer eller försöka bygga in vedertagna regler i AI-agenternas arkitektur.
Hur lär sig maskiner?
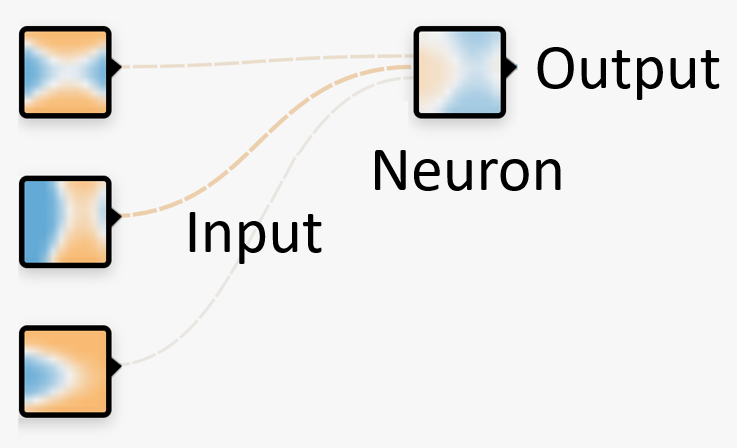
Artificiella neuroner
Artificiella neuroner är inspirerade av de biologiska neuroner som vi har i hjärnan.
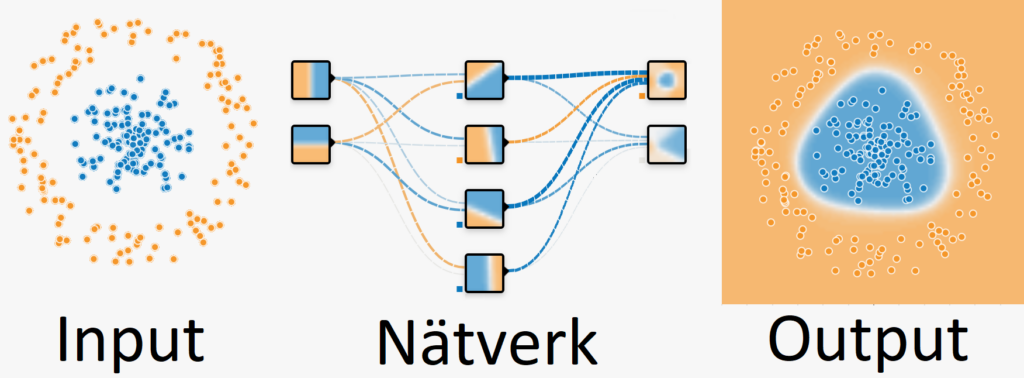
Väglett lärande (supervised learning)
I väglett lärande tränar vi nätverket genom att använda exempel, t.ex. för att klassificera data.
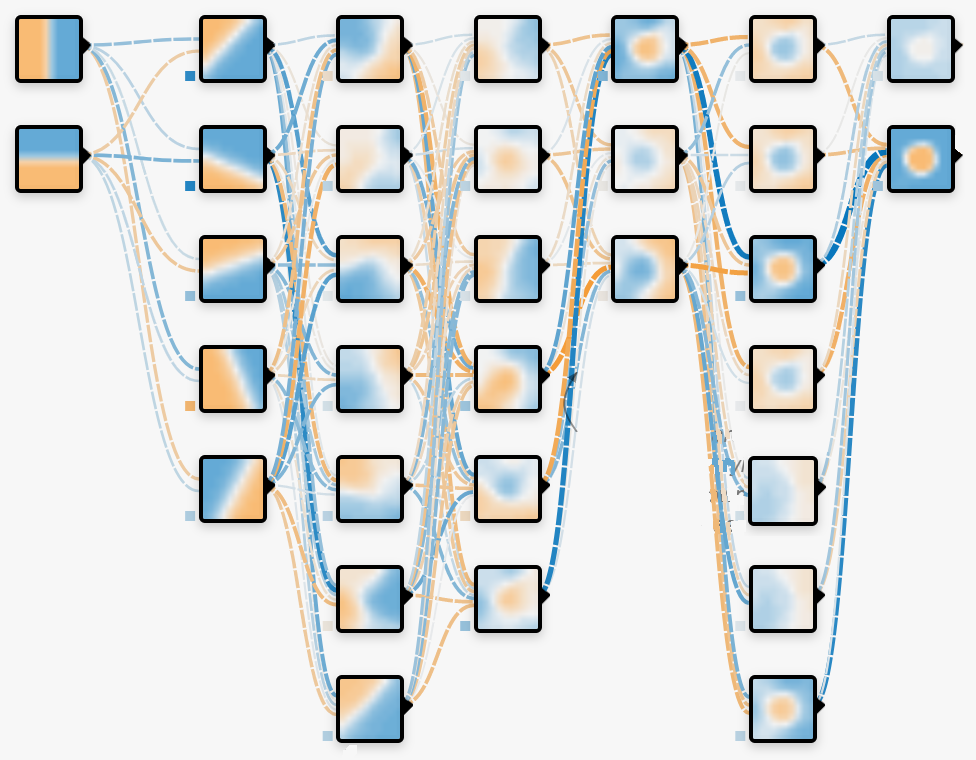
Djupinlärning (deep learning)
Inom maskininlärning kallas det för djupinlärning om nätverket innehåller många lager av neuroner (oavsett om det lyckas lära sig något vettigt eller inte).
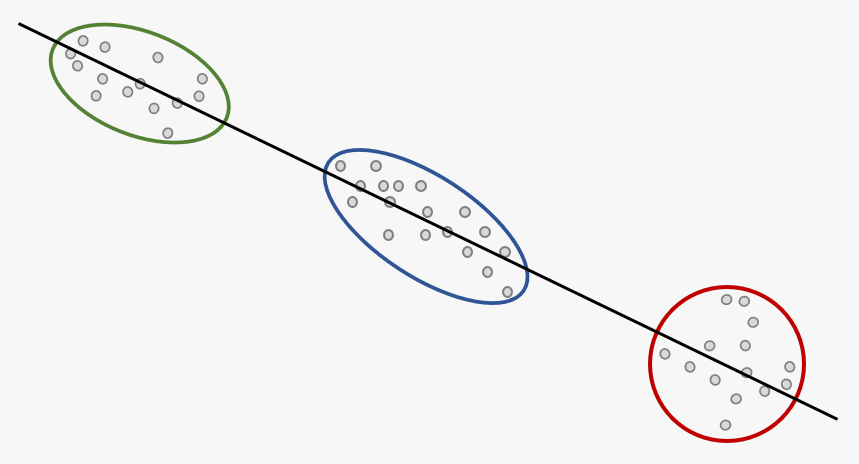
Icke-väglett lärande (unsupervised learning)
En stor fördel med icke-väglett lärande är att vi inte behöver ha exempel med korrekta svar för att träna AI-agenten.
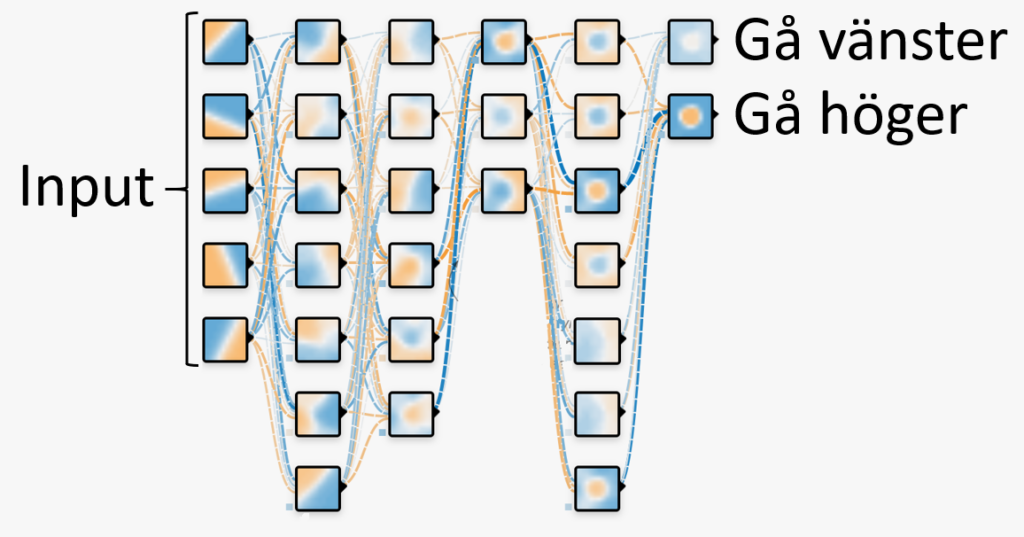
Förstärkningsinlärning
(reinforcement learning)
I förstärkningsinlärning lever oftast AI-agenten i en värld, som i ett spel, där den 1) har tillgång till viss information, kanske var den befinner sig, hur mycket guldmynt den har etc. samt 2) har förmåga att utföra olika handlingar, till exempel gå till vänster eller höger.

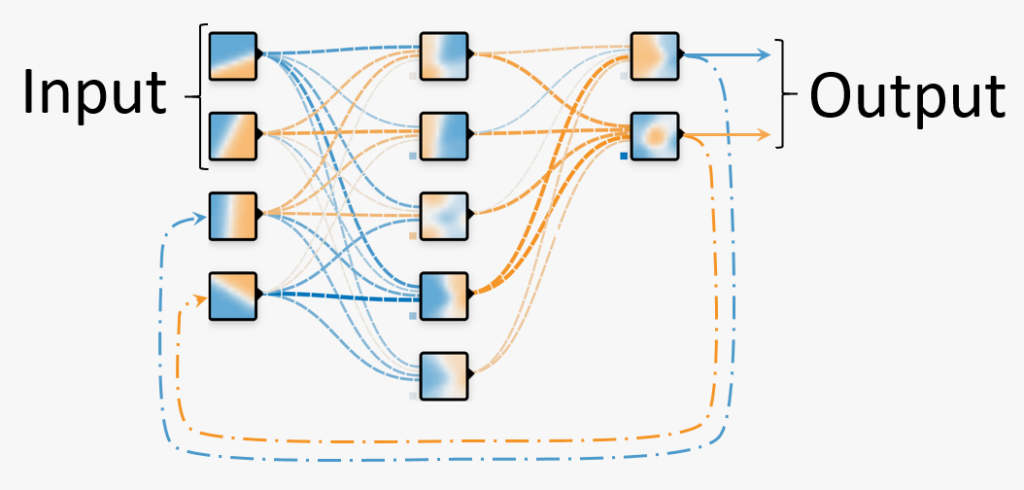
Återförande neurala nätverk
(recurrent neural networks)
I återförande neurala nätverk återförs nätverkets output för att komplettera omvärldens input. På så sätt får nätverket ett minne.
Maskininlärning och mänskliga hjärnan
Går mänskligt och maskinellt lärande verkligen att jämföra?
De elektroniska mekanismerna för inlärning i artificiella nätverk är helt annorlunda jämfört med hur biologiska neuroner förändrar sina kopplingar.
Trots det besitter både biologiska och artificiella nätverk förmågan att extrahera komplexa abstrakta slutsatser från information. Låt oss undersöka några skillnader och likheter.

Hur kan vi träna på ett effektivt sätt?
Hur skulle det vara om vi tränar våra barn med enbart väglett lärande på samma sätt som det använts för AI-agenter?

Multimodalt lärande
Om det ser ut som en anka, låter som en anka och beter sig som en anka – då är det nog en anka.

Use it or lose it!
Både biologiska och artificiella nätverk drabbas av så kallad katastrofal glömska (catastrophic forgetting).

Aktiv inlärning
Inom maskininlärning handlar aktiv inlärning om att identifiera vilken sorts träningsdata som behövs för att förbättra AI-agentens förmåga.

Närmsta utvecklingszonen
Inom pedagogiken är det känt att människor ofta lär sig snabbare i den så kallade närmsta utvecklingszonen.

Bortom traditionell AI-träning
Mycket forskning pågår för att utforska om AI-agenter kan tränas på olika sätt som liknar hur människor lär sig. Till exempel Finns det situationer där det skulle vara fördelaktigt om vi kan lära en AI-agent via instruktion eller demonstration istället för feedback eller förstärkningsinlärning där AI-agenter testar sig fram?

Sovande AI-agenter?
När människor sover så spelar hjärnan upp minnen från dagen som gått. Om man stör denna process under sömnen så försämras inlärningen.

Belöning, dopamin och förväntningar
Det är inte bara hjärnan som inspirerar AI-forskare. Resultat från maskininlärning ger även djupare förståelse av hur hjärnan fungerar. Skillnaden mellan vad vad en AI-agent förväntar sig och vad den får som belöning när den utför handlingar hade länge använts för att träna AI-agenter till att optimera sina handlingar. Detta är speciellt användbart i en värld där det är osäkert om man får belöningen eller inte vid varje tillfälle. Neuroforskare kunde använda AI-forskarnas kunskap för att förstå hur dopaminsystemet i hjärnan fungerar. AI-forskningen har nu gått ännu längre och kommit fram till att AI-agenter lär sig snabbare och bättre om de dessutom lär sig att representera sannolikhetsfördelningen för att man skall få en viss stor belöning. Teorin har sedan testats på mushjärnor och visat att de fungerar på samma sätt, vilket har fördjupat vår förståelse för dopaminsystemet ytterligare.
Att simulera en hjärna
Det pågår flera initiativ för att försöka simulera mänskliga hjärnan. forskningsresultaten från dessa projekt kommer förhoppningsvis lära oss mycket mer om hur hjärnan fungerar.

Vad kan vi lära oss om lärande?
Vad kan maskininlärning lära oss om mänskligt lärande? Och hur kan vår förståelse för hur människor lär sig hjälpa oss att skapa ännu bättre AI-agenter?
- Vilka metoder ger snabbast inlärning i olika situationer och ämnen?
- Hur kan vi använda maskininlärning för att analysera stora mängder empirisk data för att verifiera eller avfärda pedagogiska modeller?
- Hur kan AI hjälpa oss att förbättra undervisningen i skolan?
Artificiell intelligens i skolan

Individanpassat lärande
En av de mest lovande tillämpningarna av AI-teknik i skolan är sannolikt att använda den för att individanpassa lärandet.
AI-agenter skulle kunna stötta läraren genom att
- stärka ett growth mindset genom att ge lämplig feedback beroende på framsteg och hinder, samt uppmuntra eleven att försöka och våga misslyckas
- anpassa svårighetsgraden på matteuppgifterna så att de både ger utmaning och känsla av framsteg, ge ledtrådar vid rätt tillfällen
- hjälpa till att korrigera uttal av främmande språk
- dokumentera historik över elevers utveckling och sammanställa översikter för eleven, läraren och vårdnadshavare
- analysera elevers dokumenterade data, jämföra elevers utveckling med erfarenheter ifrån tidigare elever för att kunna föreslå åtgärder som visat sig vara effektiva hos elever från andra delar av landet eller världen som har liknande utvecklingsmönster
- utforma individuella scheman baserade på dataanalysen för att mer effektivt spendera tiden efter elevens behov men samtidigt synka de individuella aktiviteterna med grupp och helklassövningar
På så sätt kan AI-agenterna frigöra mer av lärares tid så att de kan fokusera på de uppgifter som ännu är för svåra för AI-agenter eller som kräver mänsklig interaktion.

Rättvisare tillgång till hjälp
AI-agenter har outtröttligt tålamod och oändligt med tid. Genom att göra dem tillgängliga för alla elever kan skolan kompensera för elevers olika socioekonomiska bakgrunder.
Vi skulle få en rättvisare utbildning där elever som behöver mer tid att träna på olika ämnen kan få stor tillgång till hjälp från AI-agenter. AI-agenternas insatser kan sedan kompletteras av lärarens avancerade undervisning och dyrbara tid. AI-agenter skulle också kunna kompensera för vårdnadshavares olika engagemang i sina barns läxläsning. En annan möjlig framtid är dock att AI-agenterna inte är tillgängliga för alla. Om AI-agenter bara blir tillgängliga för vissa av ekonomiska eller andra skäl så kommer de sannolikt istället öka skillnaderna i barns förutsättningar. Borde det vara ett barns rättighet att få tillgång till utbildningsinriktade AI-agenter? Hur förändrar AI-agenter vad “en likvärdig skola” innebär?

Minska avhopp från skolan
AI-agenter hjälper redan idag skolor i flera länder att tidigt identifiera elever som riskerar att hoppa av skolan. Insatser har därmed kunnat sättas in tidigare för att stötta eleverna och minska deras risk att hoppa av.

Rättvisa betyg
AI-agenter kan hjälpa till med att effektivt och rättvist rätta prov av olika typer.
AI, autism och inlärningssvårigheter
AI-teknik används för att stödja personer med autism och stärka deras emotionella interaktion med andra människor.
Är AI ett stöd eller övervakning?
I vissa delar av Kina använder elever ett pannband som mäter elevernas koncentrationsnivå.
Reflektera och diskutera

“Arv” och miljö
I USA togs en neural nätverksarkitektur fram som tränades till att känna igen smartphoneanvändares ansikten. Men när funktionen aktiverades i Kina uppstod problem.

Går det att träna sig in i ett hörn?
I forskning på personer med lässvårigheter kan man ibland se vissa skillnader på hur och var i hjärnan de representerar informationen.

Vad krävs för att förstå bus?
Vad krävs för att förstå och beskriva bilden?
Insikt i en AI-agents regler
De regler som AI-agenter tränar fram är gömda i nätverksarkitekturen och styrkan på kopplingarna mellan neuronerna. De flesta AI-agenter är därför duktiga på att ge bra svar på svåra frågor, men de är desto sämre på att beskriva HUR de kommit fram till svaret.

Att förstå andra
I ett experiment fanns ett bord med 25 koppar.
Emotionell kompetens – behövs läkare?
Vad som är enkelt och svårt för en AI-agent är lite kontraintuitivt.

Vad krävs för att lita på en AI-agent?
Människor får körkort efter att klara ett standardiserat uppkörningsprov.

AI-attacker
Generativa nätverk kan tränas till att lura andra AI-agenter.

Vem är ansvarig för det en AI-agent gör?
Forskare som hade tränat en chatbot på Twittermeddelanden var tvungna att stänga av AI-agenten eftersom den hade blivit ett rasistiskt internettroll ifrån det den lärt sig på Twitter.

Artificiell influencer
Vem har makten att skriva kostnadsfunktionerna för framtidens AI-agenter?

Människor som jobbar för AI-agenter
Redan idag finns det mänskliga internettroll som gör skada på samhället för egen ekonomisk vinning men även de som begår småbrott för egen överlevnad.

En digital människa?
Om vi skulle kunna simulera alla nervceller i hjärnan, skulle vi ha en människa?
Artificiell emotionell intelligens
AI-agenter börjar nå en avancerad kognitiv (tankemässiga) kapacitet men för människor är den emotionella kapaciteten minst lika viktig.
Till exempel handlar mänsklig kommunikation bara till viss del om vilka ord som faktiskt sägs. En stor del av kommunikationen ligger i tonfall, kroppsspråk och den emotionella kontexten. Även om AI-forskningen börjat utforska emotionella förmågor så har vi oerhört långt kvar. Samtidigt behöver AI-agenter inte vara emotionella experter för att ändå kunna hjälpa människor att avkoda emotionell kommunikation. En bra jämförelse är att AI-agenter kan hjälpa barn lära sig addera och subtrahera utan att kunna hjälpa dem med mer avancerad matematik. Som vi såg i avsnittet “Att förstå andra” används AI-agenter redan idag för att hjälpa personer med autism att förstå emotionella signaler på en basal nivå. Det lär dock ta lång tid tid innan vi når emotionellt mogna AI-agenter.
- Behöver AI-agenter kunna uppleva känslor för att tolka människors emotionella kommunikation?
- Behöver AI-agenter kunna uppleva känslor för att kunna kommunicera emotionell information?
- Kommer känslor bli en viktig del även för AI-agenters beslutfattande?
- I människor är känslor en intim interaktion mellan kroppsliga reaktioner och förnimmelser av lust eller olust i hjärnan. Behöver AI-agenter ha en biologisk kropp för att kunna uppleva känslor?
- Behöver AI-agenters använda sig av mekanismer som liknar dem i den mänskliga hjärnan för att kunna använda sig av “mänskliga känslor”?
- Finns det andra sorters känslor?
- Vad innebär egentligen känslor?
Människa + AI-agent = cyborg
Är det ens intressant att skapa en digital kopia av en hjärna?

AI-forskande AI-agenter
Vad innebär det att vara människa i en värld där AI-agenterna blivit så avancerade att det är de som driver AI-forskningen?

Framtidens föräldraskap?
Har du någon gång utvecklat vänskapsband eller känslor för en person som du aldrig sett, kanske en kollega i ett annat land eller en person från en dejtingsida? Kan du bli kär i någon du aldrig träffat?
- Skulle du kunna bli kär i en person som visar sig vara en AI-agent?
- Skulle du kunna älska personen som om den vore en människa?
Tänk dig ytterligare 30 år fram i tiden.
- Skulle ditt barn kunna bli kär i en AI?
- Skulle du kunna älska en AI som ditt eget barn?
- Hur skulle du känna inför att vara den sista personen i din familj som har DNA, och istället ha ett post-biologiskt barn?
- Hur skulle du känna om ditt barn gjorde ett sådant val?

Referensmaterial
Böcker

Liv 3.0: att vara människa i den artificiella intelligensens tid
Max Tegmark (2017)

Tänkandets maskineri: när AI lär från hjärnan
Martin Ingvar (2019)

Ditt framtida jag
Sara Öhrvall (2020)

Tänkande maskiner: Den artificiella intelligensens genombrott
Olle Häggström (2021)
Podcast & intervjuer
DeepMind The Podcast
med Hannah Fry
Deep learning, neural networks and the future of AI
Intervju med Yann LeCun, en av de mest framstående forskarna inom maskininlärning
Kurser

Teachable Machine – träna en maskinmodell utan programmeringskunskaper.
Lärarinstruktioner för högstadiet

Undervisningsmaterial för grundskolan.
Undervisningsmaterial för mellan- och högstadiet.

Introduktionskurs inom AI för gymnasiet/högskola. Kursen är gratis och ger högskolepoäng.
Artificial General Intelligence – föreläsningar och samtal med forskare
Externa hemsidor

duolingo research utför och sprider forskning om språkinlärning

ISTE (International Society for Technology in Education) sprider kunskap om hur teknologi kan användas i undervisning.




Granskare

Med en bakgrund som doktor inom statistisk fysik intresserar jag mig nu för hur prestandan av neurala nätverk påverkas av vilka exempel som används då nätverken tränas. För att minimera hur mycket träningsdata som krävs undersöker vi hur vi kan använda AI-agenten själv för att förstå vilken data som vi borde träna på härnäst, samt hur AI-agenten kan träna sig själv i större utsträckning.
Forskningsingenjör inom maskininlärning
Zenseact AB